
其中恶意文件的类型有感染性病毒、木马程序、挖矿程序、DDOS木马、勒索病毒等,数据总计6亿条数据说明1)训练数据(train.zip):调用记录近9000万次,文件1万多个(以文件编号汇总),字段描述

天池大赛-阿里云安全恶意程序检测的链接地址:阿里云安全恶意程序检测_学习赛_赛题与数据_天池大赛-阿里云天池
机器学习相关大赛文档可访问以上链接地址进行下载
机器学习大赛进行数据分析、特征选择、训练、测试提交之前,读懂题意很重要。看看阿里云安全恶意程序检测代码是什么,要求参赛者做什么吧
赛题与数据
赛题背景
恶意软件是一种被设计用来对目标计算机造成破坏或者占用目标计算机资源的软件,传统的恶意软件包括蠕虫、木马等,这些恶意软件严重侵犯用户合法权益,甚至将为用户及他人带来巨大的经济或其他形式的利益损失。近年来随着虚拟货币进入大众视野,挖矿类的恶意程序也开始大量涌现,黑客通过入侵恶意挖矿程序获取巨额收益。当前恶意软件的检测技术主要特征码检测、行为检测和启发式检测等,配合使用机器学习可以在一定程度上提高泛化能力,提升恶意样本的识别率
赛题说明
本题目提供的数据来自文件(windows 可执行程序)经过沙箱程序模拟运行后的API指令序列,全为windows二进制可执行程序,经过脱敏处理。本题目提供的样本数据均来自于互联网。其中恶意文件的类型有感染性病毒、木马程序、挖矿程序、DDOS木马、勒索病毒等,数据总计6亿条
数据说明
1)训练数据(train.zip):调用记录近9000万次,文件1万多个(以文件编号汇总),字段描述如下:
字段 | 类型 | 解释 |
file_id | bigint | 文件编号 |
label | bigint | 文件标签,0-正常/1-勒索病毒/2-挖矿程序/3-DDoS木马/4-蠕虫病毒/5-感染型病毒/6-后门程序/7-木马程序 |
api | string | 文件调用的API名称 |
tid | bigint | 调用API的线程编号 |
index | string | 线程中API调用的顺序编号 |
注1:一个文件调用的api数量有可能很多,对于一个tid中调用5000个api的文件,我们进行了截断,按照顺序保留了每个tid前5000个api的记录
注2:不同线程tid之间没有顺序关系,同一个tid里的index由小到大代表调用的先后顺序关系
注3:index是单个文件在沙箱执行时的全局顺序,由于沙箱执行时间有精度限制,所以会出现一个index上出现同线程或者不同线程都在执行多次api的情况,可以保证同tid内部的顺序,但不保证连续
2)测试数据(test.zip):调用记录近8000万次,文件1万多个
说明:格式除了没有label字段,其他数据规格与训练数据一致
评测指标
1.选手的结果文件包含9个字段:file_id(bigint)、和八个分类的预测概率prob0, prob1, prob2, prob3, prob4, prob5 ,prob6,prob7 (类型double,范围在[0,1]之间,精度保留小数点后5位,prob[removed]=1.0我们会替换为1.0-1e-6)。选手必须保证每一行的|prob0+prob1+prob2+prob3+prob4+prob5+prob6+prob7-1.0|<1e-6,且将列名按如下顺序写入提交结果文件的第一行,作为表头:file_id,prob0,prob1,prob2,prob3,prob4,prob5,prob6,prob7。
2.分数采用logloss计算公式如下:
logloss = -
M代表分类数,N代表测试集样本数,yij代表第i个样本是否为类别j(是~1,否~0),Pij代表选手提交的第i个样本被预测为类别j的概率(prob),最终公布的logloss保留小数点后6位。
机器学习(ML)代码详解
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltimport lightgbm as lgbfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import OneHotEncoderfrom tqdm import tqdm_notebookimport warningswarnings.filterwarnings('ignore')%matplotlib inline# 内存管理import numpy as npimport pandas as pdfrom tqdm import tqdm class _Data_Preprocess: def __init__(self): self.int8_max = np.iinfo(np.int8).max self.int8_min = np.iinfo(np.int8).min self.int16_max = np.iinfo(np.int16).max self.int16_min = np.iinfo(np.int16).min self.int32_max = np.iinfo(np.int32).max self.int32_min = np.iinfo(np.int32).min self.int64_max = np.iinfo(np.int64).max self.int64_min = np.iinfo(np.int64).min self.float16_max = np.finfo(np.float16).max self.float16_min = np.finfo(np.float16).min self.float32_max = np.finfo(np.float32).max self.float32_min = np.finfo(np.float32).min self.float64_max = np.finfo(np.float64).max self.float64_min = np.finfo(np.float64).min def _get_type(self, min_val, max_val, types): if types == 'int': if max_val <= self.int8_max and min_val >= self.int8_min: return np.int8 elif max_val <= self.int16_max <= max_val and min_val >= self.int16_min: return np.int16 elif max_val <= self.int32_max and min_val >= self.int32_min: return np.int32 return None elif types == 'float': if max_val <= self.float16_max and min_val >= self.float16_min: return np.float16 if max_val <= self.float32_max and min_val >= self.float32_min: return np.float32 if max_val <= self.float64_max and min_val >= self.float64_min: return np.float64 return None def _memory_process(self, df): init_memory = df.memory_usage().sum() / 1024 ** 2 / 1024 print('Original data occupies {} GB memory.'.format(init_memory)) df_cols = df.columns for col in tqdm_notebook(df_cols): try: if 'float' in str(df[col].dtypes): max_val = df[col].max() min_val = df[col].min #调用自定义的变量和上面定义的_get_type函数,返回数据类型存储方式对应的数值范围、数值精度 trans_types = self._get_type(min_val, max_val, 'float') #若trans_types存在,则df[col]的类型设置为trans_types if trans_types is not None: df[col] = df[col].astype(trans_types) elif 'int' in str(df[col].dtypes): max_val = df[col].max() min_val = df[col].min() trans_types = self._get_type(min_val, max_val, 'int') if trans_types is not None: df[col] = df[col].astype(trans_types) except: print(' Can not do any process for column, {}.'.format(col)) afterprocess_memory = df.memory_usage().sum() / 1024 ** 2 / 1024 print('After processing, the data occupies {} GB memory.'.format(afterprocess_memory)) return dfmemory_process = _Data_Preprocess()# 数据读取path = '../security_data/' #注:根据个人数据源存储目录输入train = pd.read_csv(path + 'security_train.csv') #读取训练数据集test = pd.read_csv(path + 'security_test.csv') #读取测试数据集train.head() # 打印训练数据集的前5条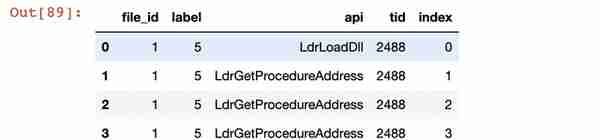
# 创建simple_sts_features函数,获取api、tid、index的总数和唯一值总数#nunique():python的内置函数,对重复的数获取一次,统计不同数之间的总数def simple_sts_features(df): simple_fea = pd.DataFrame() simple_fea['file_id'] = df['file_id'].unique() simple_fea = simple_fea.sort_values('file_id') df_grp = df.groupby('file_id') simple_fea['file_id_api_count'] = df_grp['api'].count().values simple_fea['file_id_api_nunique'] = df_grp['api'].nunique().values simple_fea['file_id_tid_count'] = df_grp['tid'].count().values simple_fea['file_id_tid_nunique'] = df_grp['tid'].nunique().values simple_fea['file_id_index_count'] = df_grp['index'].count().values simple_fea['file_id_index_nunique'] = df_grp['index'].nunique().values return simple_fea#simple_train_fea1是指统计分析训练数据集中的api、tid、index的总数和唯一值总数# %%time:打印simple_train_fea1运行所用的时间%%timesimple_train_fea1 = simple_sts_features(train)%%timesimple_test_fea1 = simple_sts_features(test)#创建simple_numerical_sts_features函数,获取tid、index的平均值、最小值、标准偏差、最大值def simple_numerical_sts_features(df): simple_numerical_fea = pd.DataFrame() simple_numerical_fea['file_id'] = df['file_id'].unique() simple_numerical_fea = simple_numerical_fea.sort_values('file_id') df_grp = df.groupby('file_id') simple_numerical_fea['file_id_tid_mean'] = df_grp['tid'].mean().values simple_numerical_fea['file_id_tid_min'] = df_grp['tid'].min().values simple_numerical_fea['file_id_tid_std'] = df_grp['tid'].std().values simple_numerical_fea['file_id_tid_max'] = df_grp['tid'].max().values simple_numerical_fea['file_id_index_mean']= df_grp['index'].mean().values simple_numerical_fea['file_id_index_min'] = df_grp['index'].min().values simple_numerical_fea['file_id_index_std'] = df_grp['index'].std().values simple_numerical_fea['file_id_index_max'] = df_grp['index'].max().values return simple_numerical_fea%%timesimple_train_fea2 = simple_numerical_sts_features(train)%%timesimple_test_fea2 = simple_numerical_sts_features(test)#构建特征值,获取以file_id、api分组,tid的总数def api_pivot_count_features(df): #以file_id、api分组获取tid的总数 如file_id=1,api=CoCreateInstance涉及15个线程,即api_tid_count=15 tmp = df.groupby(['file_id','api'])['tid'].count().to_frame('api_tid_count').reset_index() #做一个数据透视表,以file_id为索引,api的名称做栏,值为某api在某file_id涉及的线程总数 tmp_pivot = pd.pivot_table(data=tmp,index = 'file_id',columns='api',values='api_tid_count',fill_value=0) #对数据透视表的栏做重新赋值 tmp_pivot.columns = [tmp_pivot.columns.names[0] + '_pivot_'+ str(col) for col in tmp_pivot.columns] #将tmp_pivot.columns应用到数据透视表 tmp_pivot.reset_index(inplace = True) #调用memory_process._memory_process,计算tmp_pivot占用的内存大小 tmp_pivot = memory_process._memory_process(tmp_pivot) return tmp_pivot %%timesimple_train_fea3 = api_pivot_count_features(train)%%timesimple_test_fea3 = api_pivot_count_features(test)#构建特征值,获取以file_id、api分组,tid的唯一值总数def api_pivot_nunique_features(df): tmp = df.groupby(['file_id','api'])['tid'].nunique().to_frame('api_tid_nunique').reset_index() tmp_pivot = pd.pivot_table(data=tmp,index = 'file_id',columns='api',values='api_tid_nunique',fill_value=0) tmp_pivot.columns = [tmp_pivot.columns.names[0] + '_pivot_'+ str(col) for col in tmp_pivot.columns] tmp_pivot.reset_index(inplace = True) tmp_pivot = memory_process._memory_process(tmp_pivot) return tmp_pivot %%timesimple_train_fea4 = api_pivot_count_features(train)%%timesimple_test_fea4 = api_pivot_count_features(test)#获取训练数据集的file_id、label两行,并去重只保留数据第一次出现的行数train_label = train[['file_id','label']].drop_duplicates(subset = ['file_id','label'], keep = 'first')#获取测试数据集的file_id,并去重只保留第一次出现的行数test_submit = test[['file_id']].drop_duplicates(subset = ['file_id'], keep = 'first')
#将定义的特征合并train_data = train_label.merge(simple_train_fea1, on ='file_id', how='left')train_data = train_data.merge(simple_train_fea2, on ='file_id', how='left')train_data = train_data.merge(simple_train_fea3, on ='file_id', how='left')train_data = train_data.merge(simple_train_fea4, on ='file_id', how='left')test_submit = test_submit.merge(simple_test_fea1, on ='file_id', how='left')test_submit = test_submit.merge(simple_test_fea2, on ='file_id', how='left')test_submit = test_submit.merge(simple_test_fea3, on ='file_id', how='left')test_submit = test_submit.merge(simple_test_fea4, on ='file_id', how='left')# 打印train_data,查看数据信息train_data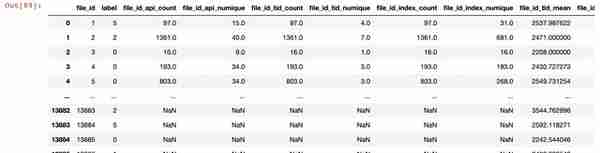
到这里,数据处理、特征选取算是完成了,下面进行模型、选取、验证、优化
### 评估指标构建def lgb_logloss(preds,data): labels_ = data.get_label() classes_ = np.unique(labels_) preds_prob = [] for i in range(len(classes_)): preds_prob.append(preds[i*len(labels_):(i+1) * len(labels_)] ) preds_prob_ = np.vstack(preds_prob) loss = [] for i in range(preds_prob_.shape[1]): sum_ = 0 for j in range(preds_prob_.shape[0]): pred = preds_prob_[j,i] if j == labels_[i]: sum_ += np.log(pred) else: sum_ += np.log(1 - pred) loss.append(sum_) return 'loss is: ',-1 * (np.sum(loss) / preds_prob_.shape[1]),False说实话,模型选择这块还是薄弱项,lgb_logloss函数没有看懂。等随着机器学习的基础打牢了,再对lgb_logloss函数的代码进行细致分析
基于Light GBM的模型验证
#定义模型验证所需要的特征栏train_features = [col for col in train_data.columns if col not in ['label','file_id']]train_label = 'label'%%timefrom sklearn.model_selection import StratifiedKFold,KFoldparams = { 'task':'train', 'num_leaves': 255, 'objective': 'multiclass', 'num_class': 8, 'min_data_in_leaf': 50, 'learning_rate': 0.05, 'feature_fraction': 0.85, 'bagging_fraction': 0.85, 'bagging_freq': 5, 'max_bin':128, 'random_state':100 } # KFold 是 sklearn 包中用于交叉验证的函数。在机器学习中,样本量不充足时,通常使用交叉训练验证folds = KFold(n_splits=5, shuffle=True, random_state=15)#返回len(train) * len(train)全零矩阵oof = np.zeros(len(train))predict_res = 0models = []#交叉验证 for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_data)): print("fold n°{}".format(fold_)) trn_data = lgb.Dataset(train_data.iloc[trn_idx][train_features], label=train_data.iloc[trn_idx][train_label].values) val_data = lgb.Dataset(train_data.iloc[val_idx][train_features], label=train_data.iloc[val_idx][train_label].values) clf = lgb.train(params, trn_data, num_boost_round=2000,valid_sets=[trn_data,val_data], verbose_eval=50, early_stopping_rounds=100, feval=lgb_logloss) models.append(clf)#定义尺寸,进行绘图plt.figure(figsize=[10,8])#sns.heatmap:绘制热力图#iloc():主要作用是用来获取Dataframe结构对象之中前10000行,第1列-20列的数据#corr():相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差sns.heatmap(train_data.iloc[:10000, 1:21].corr())# 特征重要性分析feature_importance = pd.DataFrame()feature_importance['fea_name'] = train_featuresfeature_importance['fea_imp'] = clf.feature_importance()feature_importance = feature_importance.sort_values('fea_imp', ascending = False)feature_importance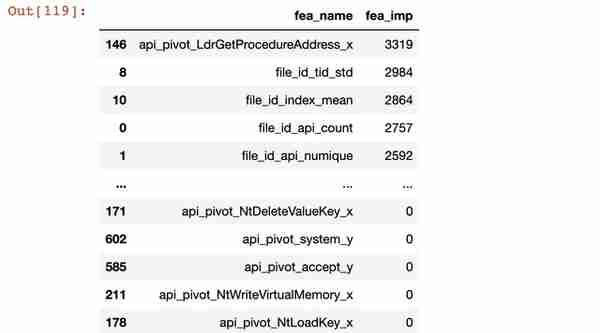
plt.figure(figsize = [20, 10,])plt.figure(figsize = [20, 10,])sns.barplot(x = feature_importance.iloc[:10]['fea_name'], y = feature_importance.iloc[:10]['fea_imp'])
plt.figure(figsize=[20,10,])sns.barplot(x = feature_importance['fea_name'], y = feature_importance['fea_imp'])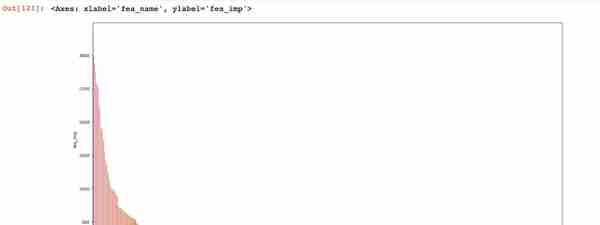
模型测试
pred_res = 0flod = 5for model in models: pred_res += model.predict(test_submit[train_features]) * 1.0 /flodtest_submit['prob0'] = 0test_submit['prob1'] = 0test_submit['prob2'] = 0test_submit['prob3'] = 0test_submit['prob4'] = 0test_submit['prob5'] = 0test_submit['prob6'] = 0test_submit['prob7'] = 0test_submit[['prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']] = pred_restest_submit[['file_id','prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']].to_csv('baseline2.csv', index = None)博客参考链接:阿里云天池大赛赛题(机器学习)——阿里云安全恶意程序检测(完整代码)_全栈O-Jay的博客-CSDN博客
猜你喜欢
-
与华为最有关的股票(与华为最有关的股票有哪些)
综上所述华为盘古大模型在模型规模,训练数据预训练任务和推理速度等方面都有优势,这使得它在中文自然语言处理领域具有很大的潜力和应用前景
